数论基础 整除 对于整数
模运算性质 在模运算的意义下,
同余 对于整数
质数 试除法判定质数 题干 给定
输入格式 第一行包含整数
接下来
输出格式 共 Yes,否则输出 No。
数据范围
输入样例: 输出样例: 思路分析 直接使用试除法判断是否为质数即可。对于每个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;const int N = 1e5 + 9 ;int n;bool is_prime (int x) if (x <= 1 ) return false ; for (int i = 2 ; i <= x / i; i++) if (x % i == 0 ) return false ; return true ; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); cin >> n; while (n--) { int x; cin >> x; if (is_prime (x)) cout << "Yes" << '\n' ; else cout << "No" << '\n' ; } }
分解质因数 题干 给定
输入格式 第一行包含整数
输出格式 对于每个正整数
每个正整数的质因数全部输出完毕后,输出一个空行。
数据范围
输入样例: 输出样例: 思路分析 使用试除法分解质因数即可。对于每个数
注意:一个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;int n;void divide (int x) for (int i = 2 ; i <= x / i; i++) if (x % i == 0 ) { int cnt = 0 ; while (x % i == 0 ) { x /= i; cnt++; } cout << i << ' ' << cnt << '\n' ; } if (x > 1 ) cout<<x<<' ' <<1 <<'\n' ; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); cin >> n; while (n--) { int x; cin >> x; divide (x); cout<<'\n' ; } }
筛质数 题干 给定一个正整数
输入格式 共一行,包含整数
输出格式 共一行,包含一个整数,表示
数据范围
输入样例: 输出样例: 思路分析 筛法1 :埃氏筛法,遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;const int N = 1e6 + 10 ;bool st[N]; int primes[N]; int idx; void get_primes (int n) for (int i = 2 ; i <= n; i++) { if (!st[i]) { primes[++idx] = i; for (int j = 2 * i; j <= n; j += i) st[j] = true ; } } } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; get_primes (n); cout << idx; }
筛法2:线性筛法,遍历
为什么是线性?这样的筛法保证每个数只会被它的最小质因数筛掉一次。
如果
如果
综上,每个数只会被它的最小质因数筛掉,因此时间复杂度为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std;const int N = 1e6 + 9 ;bool st[N]; int primes[N]; int idx; void get_primes (int n) for (int i = 2 ; i <= n; i++) { if (!st[i]) primes[++idx] = i; for (int j = 1 ; j <= idx && primes[j] <= n / i; j++) { st[i * primes[j]] = true ; if (i % primes[j] == 0 ) break ; } } } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; get_primes (n); cout << idx; }
约数 试除法求约数 题干 给定
输入格式 第一行包含整数
输出格式 输出共
数据范围
输入样例: 输出样例: 思路分析 使用试除法求约数。对于每个数 vector<int>存储,最后sort排序后输出。
注意:如果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <bits/stdc++.h> using namespace std;vector<int > get_divisors (int x) vector<int > divisors; for (int i = 1 ; i <= x / i; i++) { if (x % i == 0 ) { divisors.push_back (i); if (i != x / i) divisors.push_back (x / i); } } sort (divisors.begin (),divisors.end ()); return divisors; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int x; cin >> x; vector<int > res = get_divisors (x); for (auto ele : res) cout << ele << ' ' ; cout << '\n' ; } }
约数个数 题干 给定
输入格式 第一行包含整数
输出格式 输出一个整数,表示所给正整数的乘积的约数个数,答案需对
数据范围
输入样例: 输出样例: 思路分析 使用试除法分解质因数,统计每个质因数的指数。根据约数个数的公式,如果一个数 unordered_map<int,int>存储质因数及其对应的指数。最后计算约数个数时需要对
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <bits/stdc++.h> using namespace std;using ll = long long ;const int mod = 1e9 + 7 ;unordered_map<int ,int > factors; void get_divisors (int x) for (int i = 2 ; i <= x / i; i++) { while (x % i ==0 ) { x /= i; factors[i]++; } } if (x > 1 ) factors[x]++; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int x; cin >> x; get_divisors (x); } ll res = 1 ; for (auto ele : factors) res = res * (1 + ele.second) % mod; cout << res; }
约数之和 题干 给定
输入格式 第一行包含整数
输出格式 输出一个整数,表示所给正整数的乘积的约数之和,答案需对
数据范围
输入样例: 输出样例: 思路分析 使用试除法分解质因数,统计每个质因数的指数。根据约数之和的公式,如果一个数 unordered_map<int,int>存储质因数及其对应的指数。最后计算约数之和时需要对
注意:直接使用上述公式计算可能会导致除法问题,因此可以使用等比数列的递推关系来计算每个质因数的约数之和:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> using namespace std;using ll = long long ;const int mod = 1e9 + 7 ;unordered_map<int , int > factors; void get_divisors (int x) for (int i = 2 ; i <= x / i; i++) { while (x % i == 0 ) { x /= i; factors[i]++; } } if (x > 1 ) factors[x]++; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int x; cin >> x; get_divisors (x); } ll res = 1 ; for (auto ele : factors) { ll tmp = 1 ; int factor = ele.first, times = ele.second; for (int i = 1 ; i <= times; i++) tmp = (1 + tmp * factor) % mod; res = res * tmp % mod; } cout << res; }
最大公约数 题干 给定
输入格式 第一行包含整数
接下来
输出格式 输出共
数据范围
输入样例: 输出样例: 求最大公约数可以使用辗转相除法(欧几里得算法)。对于每对数
为什么辗转相除法正确?设
补充:有公式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <bits/stdc++.h> using namespace std;int gcd (int a, int b) if (!b) return a; return gcd (b, a % b); } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int a, b; cin >> a >> b; cout << gcd (a, b) << '\n' ; } }
欧拉函数
亦即:
对于欧拉函数,有欧拉定理 :若
当 费马小定理 :若
欧拉函数 题干 给定
输入格式 第一行包含整数
输出格式 输出共
数据范围
输入样例: 输出样例: 思路分析 使用试除法分解质因数,将质因数代入公式计算即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;typedef long long ll;ll euler (int x) ll res = x; for (int i = 2 ; i <= x / i; i++) { if (x % i == 0 ) { res = res * (i - 1 ) / i; while (x % i == 0 ) x /= i; } } if (x > 1 ) res = res * (x - 1 ) / x; return res; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int x; cin >> x; cout << euler (x) << '\n' ; } }
筛法求欧拉函数 题干 给定一个正整数
输入格式 共一行,包含一个整数
输出格式 共一行,包含一个整数,表示
数据范围
输入样例: 输出样例: 思路分析 这类筛某种数的问题,可以根据类似线性筛法的思路来实现。观察欧拉函数的公式:
如果两个数
如果两个数
若
若
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> using namespace std;typedef long long ll;const int N = 1e6 + 10 ;int n;int phi[N], primes[N], idx;bool st[N];void get_eulers (int n) phi[1 ] = 1 ; for (int i = 2 ; i <= n; i++) { if (!st[i]) { phi[i] = i - 1 ; primes[++idx] = i; } for (int j = 1 ; j <= idx && primes[j] <= n / i; j++) { st[i * primes[j]] = true ; if (i % primes[j] == 0 ) { phi[i * primes[j]] = phi[i] * primes[j]; break ; } else phi[i * primes[j]] = phi[i] * (primes[j] - 1 ); } } } int main () cin >> n; get_eulers (n); ll res = 0 ; for (int i = 1 ; i <= n; i++) res += phi[i]; cout << res << '\n' ; return 0 ; }
快速幂 快速幂 题干 给定
输入格式 第一行包含整数
输出格式 对于每组数据,输出一个结果,表示
每个结果占一行。
数据范围
输入样例: 输出样例: 思路分析 快速计算、 、 、 、 、 、 、 , 则 、
预处理方法:如果已知
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;typedef long long ll;ll qmi (int a, int k, int p) ll res = 1 ; while (k) { if (k & 1 ) res = res * a % p; k >>= 1 ; a = (ll) a * a % p; } return res; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int a, k, p; cin >> a >> k >> p; cout << qmi (a, k, p) << '\n' ; } return 0 ; }
快速幂求逆元 题干 给定 impossible。
注意 :请返回在
乘法逆元的定义
若整数
输入格式 第一行包含整数
接下来
输出格式 输出共 impossible。
数据范围
输入样例: 输出样例: 思路分析 为何需要逆元? 在模运算中,有加减法与乘法的分配律:
加减法:
乘法:
设
逆元一定存在吗? 但我们总能找到这样的
设
如何求逆元? 由当 ,根据费马小定理,有
当 ,可以使用扩展欧几里得算法求解。具体见下一题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> typedef long long ll;using namespace std;ll qmi (int a, int k, int p) ll res = 1 ; while (k) { if (k & 1 ) res = res * a % p; k >>= 1 ; a = (ll)a * a % p; } return res; } int gcd (int a, int b) if (a % b == 0 ) return b; return gcd (b, a % b); } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int a, p; cin >> a >> p; if (gcd (a, p) == 1 ) cout << qmi (a, p - 2 , p) << '\n' ; else cout << "impossible" << '\n' ; } }
扩展欧几里得算法 扩展欧几里得算法 题干 给定
输入格式 第一行包含整数
输出格式 输出共
本题答案不唯一,输出任意满足条件的
数据范围
输入样例: 输出样例: 思路分析 先介绍一个定理:
裴蜀定理 设
证明:
对于第二部分,我们只需要举出一组
扩展欧几里得算法 首先,欧几里得算法的递推公式是
而对于齐次不定方程
由线性代数的知识”非齐次通解=非齐次特解+齐次通解”,我们可以得到原方程
同理,如果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bits/stdc++.h> using namespace std;int exgcd (int a, int b, int &x, int &y) if (!b) { x = 1 , y = 0 ; return a; } int x1, y1, gcd = exgcd (b, a % b, x1, y1); x = y1; y = x1 - a / b * y1; return gcd; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int a, b, x, y; cin >> a >> b; exgcd (a, b, x, y); cout << x << ' ' << y << '\n' ; } }
线性同余方程 题干 给定 impossible。
输入格式 第一行包含整数
输出格式 输出共 impossible。
输出答案必须在 int 范围之内。
数据范围
输入样例: 输出样例: 思路分析 方程
如果
注意:当
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> typedef long long ll;using namespace std;int exgcd (int a, int b, int &x, int &y) if (!b) { x = 1 , y = 0 ; return a; } int x1, y1, gcd = exgcd (b, a % b, x1, y1); x = y1; y = x1 - a / b * y1; return gcd; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { int a, b, m, x, y; cin >> a >> b >> m; int gcd = exgcd (a, m, x, y); if (b % gcd) cout << "impossible" << '\n' ; else cout << (ll)b / gcd * x % m << '\n' ; } }
中国剩余定理 表达整数的奇怪方式 题干 给定
输入格式 第
输出格式 输出最小非负整数
数据范围
输入样例: 输出样例: 思路分析 求组合数 求组合数 I 题干 给定 ,
输入格式 第一行包含整数
接下来
输出格式 共
数据范围
输入样例: 输出样例: 思路分析 根据组合数的递推公式
注意:开始时要预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 2010 , mod = 1e9 + 7 ;ll c[N][N]; int main () for (int i = 0 ; i < N; i++) for (int j = 0 ; j <= i; j++) if (!j) c[i][j] = 1 ; else c[i][j] = (c[i - 1 ][j - 1 ] + c[i - 1 ][j]) % mod; int n; cin >> n; while (n--) { int a, b; cin >> a >> b; cout << c[a][b] << '\n' ; } return 0 ; }
求组合数 II 题干 给定 ,
输入格式 第一行包含整数
输出格式 共
数据范围
输入样例: 输出样例: 思路分析 本题数据范围为
预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 1e5 + 10 , mod = 1e9 + 7 ;ll fact[N], infact[N]; ll qmi (int a, int k, int p) ll res = 1 ; while (k) { if (k & 1 ) res = res * a % p; k >>= 1 ; a = (ll)a * a % p; } return res; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; fact[0 ] = 1 ; for (int i = 1 ; i < N; i++) fact[i] = fact[i - 1 ] * i % mod; for (int i = 0 ; i < N; i++) infact[i] = qmi (fact[i], mod - 2 , mod); while (n--) { int a, b; cin >> a >> b; cout << fact[a] * infact[b] % mod * infact[a - b] % mod << '\n' ; } return 0 ; }
求组合数 III 题干 给定
输入格式 第一行包含整数
接下来
输出格式 共
数据范围
输入样例: 输出样例: 思路分析 由于 卢卡斯定理 来计算。
Lucas定理
下面给出证明(了解即可):
首先先把
接着证明一个引理:
我们把
= (1 + x)^{a_k p^k} \times (1 + x)^{a_{k-1} p^{k-1}} \times \dots \times (1 + x)^{a_1 p} \times (1 + x)^{a_0}由 可 知
由 p \ {k-1} \dots b_1 b_0)p则 {k-1} \dots a_1 = \lfloor \frac{a}{p} \rfloor \因 此 整 理 得 到
Lucas定理如何应用? 我们可以写一个lucas(ll a, ll b)函数,当 lucas(a/p, b/p) * C_{a mod p}^{b mod p} mod p。
1 2 3 4 5 6 ll lucas (ll a, ll b) if (a < p && b < p) return c[a][b]; return (ll)lucas (a / p, b / p) * C[a % p][b % p] % p; }
由于我们还要求 C(int a, int b) 函数,使用阶乘定义式计算组合数。
由于
因为
1 2 3 4 5 6 7 8 9 10 int C (int a, int b) int res = 1 ; for (int i = 1 , j = a; i <= b; i++, j--) { res = (ll)res * j % p; res = (ll)res * qmi (i, p - 2 , p) % p; } return res; }
再加上快速幂代码,得到最后的AC代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 5010 ;int qmi (int a, int k, int p) ll res = 1 ; while (k) { if (k & 1 ) res = res * a % p; k >>= 1 ; a = (ll)a * a % p; } return res; } int C (int a, int b, int p) ll res = 1 ; for (int i = 1 , j = a; i <= b; i++, j--) { res = res * j % p; res = res * qmi (i, p - 2 , p) % p; } return res; } int lucas (ll a, ll b, int p) if (a < p && b < p) return C (a, b, p); return (ll)lucas (a / p, b / p, p) * C (a % p, b % p, p) % p; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); int n; cin >> n; while (n--) { ll a, b; int p; cin >> a >> b >> p; cout << lucas (a, b, p) << '\n' ; } }
求组合数 IV 题干 输入
注意结果可能很大,需要使用高精度计算。
输入格式 共一行,包含两个整数
输出格式 共一行,输出
数据范围
输入样例: 输出样例: 思路分析 如果按照组合数的公式来,我们不仅要写高精度乘法,还要写高精度除法,这样结果会过于复杂。我们可以考虑分解质因数法,即将组合数的分子和分母的质因数分解,统计每个质因数的指数,将分子和分母的质因数指数相减,得到最终结果的质因数指数。这样就可以避免除法运算。
接下来我们需要一个函数返回一个数的质因数分解结果。虽然试除法这题理论上也能过,但我们有更快的方法。
对于
我们有了计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 5010 ;bool st[N];int primes[N], idx;int sum[N];void get_primes (int n) for (int i = 2 ; i <= n; i++) { if (!st[i]) primes[++idx] = i; for (int j = 1 ; primes[j] <= n / i && j <= idx; j++) { st[i * primes[j]] = true ; if (i % primes[j] == 0 ) break ; } } } int fact (int n, int p) int res = 0 ; while (n) { res += n / p; n /= p; } return res; } vector<int > mul (vector<int > A, int b) int t = 0 ; vector<int > ans; for (int i = 0 ; i < A.size (); i++) { t += A[i] * b; ans.push_back (t % 10 ); t /= 10 ; } while (t) { ans.push_back (t % 10 ); t /= 10 ; } return ans; } int main () int a, b; cin >> a >> b; get_primes (a); for (int i = 1 ; i <= idx; i++) sum[primes[i]] = fact (a, primes[i]) - fact (b, primes[i]) - fact (a - b, primes[i]); vector<int > res; res.push_back (1 ); for (int i = 1 ; i <= idx; i++) for (int j = 1 ; j <= sum[primes[i]]; j++) res = mul (res, primes[i]); for (int i = res.size () - 1 ; i >= 0 ; i--) cout << res[i]; return 0 ; }
Catalan数 满足条件的01序列 题干 给定
输出的答案对
输入格式 共一行,包含整数
输出格式 共一行,包含一个整数,表示答案。
数据范围
输入样例: 输出样例: 思路分析
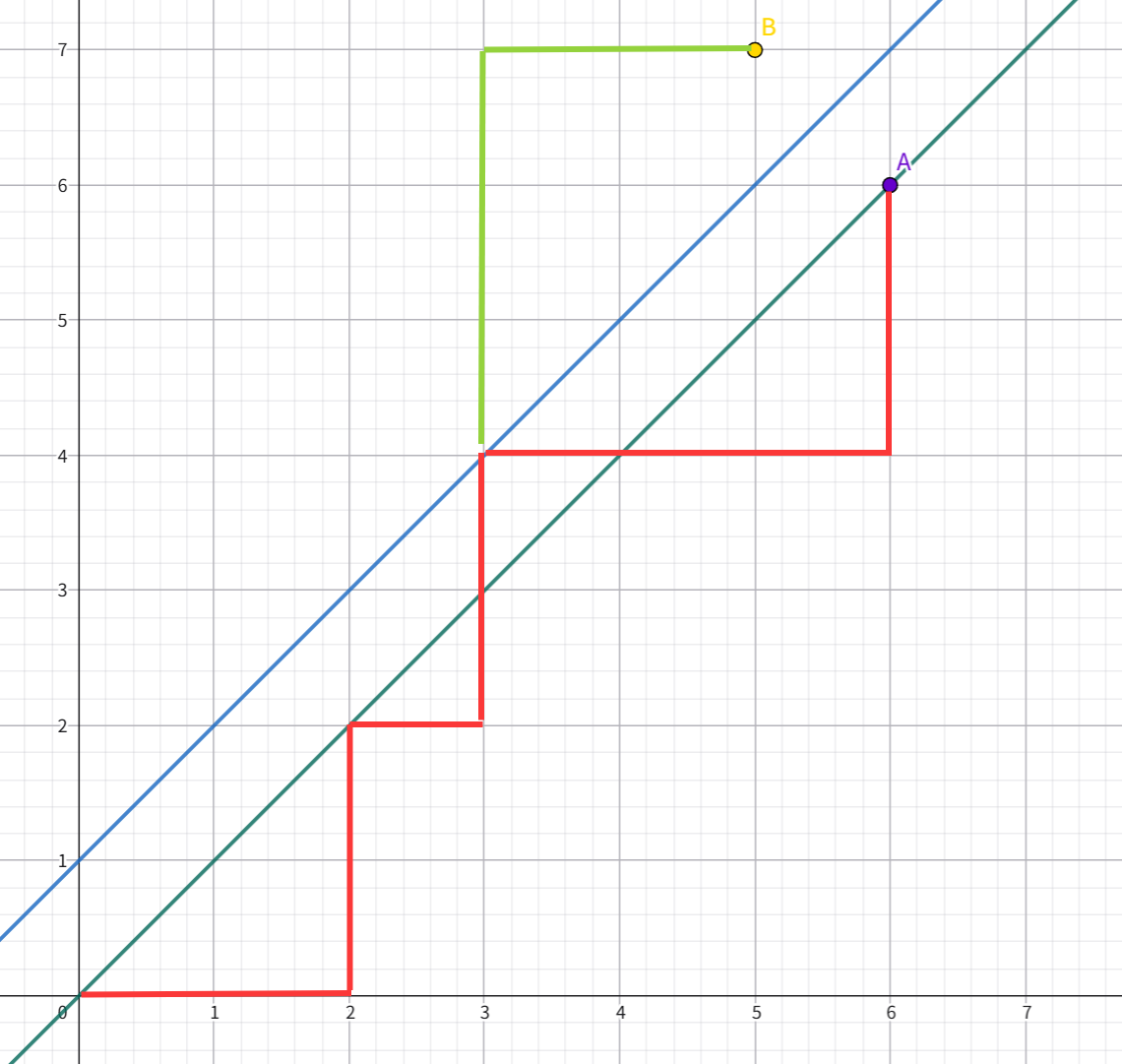
不妨将
此时作直线 ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int mod = 1e9 + 7 ;ll qmi (int a, int k, int p) ll res = 1 ; while (k) { if (k & 1 ) res = res * a % p; k >>= 1 ; a = (ll)a * a % p; } return res; } int main () int n; cin >> n; ll res = 1 ; for (int i = 1 , j = 2 * n; i <= n; i++, j--) { res = res * j % mod; res = res * qmi (i, mod - 2 , mod) % mod; } res = res * qmi (n + 1 , mod - 2 , mod) % mod; cout << res; }
容斥原理 能被整除的数 题干 给定一个整数
请你求出
输入格式 第一行包含整数
第二行包含
输出格式 输出一个整数,表示满足条件的整数的个数。
数据范围
输入样例: 输出样例: 思路分析
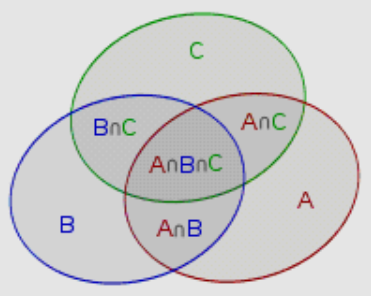
由Venn图可知,三个集合的容斥原理为
由于
我们只需要枚举所有的子集,计算每个子集的大小,根据容斥原理,如果子集是奇数个质数的乘积,则加上该子集的大小,否则减去该子集的大小。
显然共有 乘 积
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 20 ;int p[N];int main () int n, m; cin >> n >> m; for (int i = 0 ; i < m; i++) cin >> p[i]; int res = 0 ; for (int i = 1 ; i < 1 << m; i++) { int t = 1 , cnt = 0 ; for (int j = 0 ; j < m; j++) { if (i >> j & 1 ) { cnt++; if ((ll)t * p[j] > n) { t = -1 ; break ; } t *= p[j]; } } if (t != -1 ) { if (cnt & 1 ) res += n / t; else res -= n / t; } } cout << res << '\n' ; return 0 ; }
博弈论 891.Nim游戏 题干 给定
问如果两人都采用最优策略,先手是否必胜。
输入格式 第一行包含整数
第二行包含
输出格式 如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围 每 堆 石 子 数
输入样例: 输出样例: 思路分析 先以
设两堆石子的数量分别为
设如果两堆石子的数量分别为
我们可以将所有状态分为两类:先手必胜状态和先手必败状态。
对于先手必胜状态,存在一种操作,使得这次操作后变为先手必败状态。此时对面必败,则我方必胜。
对于先手必败状态,无论做出什么操作,都会变为先手必胜状态。此时对面必胜,则我方必败。
我们想:是否存在一种运算,使得其运算性质与Nim游戏的输赢状态完全一致?异或 运算就是我们要找的答案。
Nim和 自然数 Nim 和定义为
Nim和与Nim游戏的关系 Nim游戏中,状态
证明
若
若
若
因此异或运算Nim和的规则与Nim游戏完全相同,因此我们可以用异或运算计算一个Nim游戏是否为先手必胜。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <bits/stdc++.h> using namespace std;int main () int n; cin >> n; int res = 0 ; while (n--) { int x; cin >> x; res ^= x; } if (res) cout << "Yes" << '\n' ; else cout << "No" << '\n' ; }
892.台阶-Nim游戏 现在,有一个
两位玩家轮流操作,每次操作可以从任意一级台阶上拿若干个石子放到下一级台阶中(不能不拿)。
已经拿到地面上的石子不能再拿,最后无法进行操作的人视为失败。
问如果两人都采用最优策略,先手是否必胜。
输入格式 第一行包含整数
第二行包含
输出格式 如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
输入样例: 输出样例: 思路分析 我们先枚举几个台阶数较小的情况,找找规律:
当
当
如果
如果
也就是说当
我们考虑一个情况:如果只有偶数台阶上有石子,而奇数台阶上没有石子,那么无论先手如何操作,后手都可以将先手从偶数台阶拿到奇数台阶的石子再拿回偶数台阶,从而保证奇数台阶始终没有石子,因此后手必胜,先手必败。
提出一个假设:偶数台阶的石子情况可能不影响整个有向图游戏的结果。
也就是说,整个有向图游戏的结果只与
当奇数台阶有石子并且
也就是说,若奇数台阶异或和不为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <bits/stdc++.h> using namespace std;int main () int n; cin >> n; int res = 0 ; for (int i = 1 ; i <= n; i++) { int x; cin >> x; if (i & 1 ) res ^= x; } if (res) cout << "Yes" << '\n' ; else cout << "No" << '\n' ; return 0 ; }
893.集合-Nim游戏 题干 给定
现在有两位玩家轮流操作,每次操作可以从任意一堆石子中拿取石子,每次拿取的石子数量必须包含于集合
问如果两人都采用最优策略,先手是否必胜。
输入格式 第一行包含整数
第二行包含
第三行包含整数
第四行包含
输出格式 如果先手方必胜,则输出 Yes。No。
数据范围
输入样例: 输出样例: 思路分析 先介绍一个函数:
Sprague-Grundy定理 对于一个无向图 表示的无环博弈 ,每个状态对应一个非负整数,称为该状态的SG值 。SG值的定义如下:
终止状态的SG值为
其他状态的SG值为所有后继状态的SG值的Mex值。
对于多个子博弈的合成博弈,其SG值为各个子博弈SG值的异或和。
一个状态是先手必败状态,当且仅当该状态的SG值为
一个状态是先手必胜状态,当且仅当该状态的SG值不为
对于Nim游戏,每堆石子的数量即为该堆石子的SG值,整个游戏的SG值为各堆石子数量的异或和。
对于本题,设
对于石子数量为
对于石子数量为
对于石子数量为
对于石子数量为
对于石子数量为
以此类推,可以计算出 Yes。
为什么这个定理正确? 先从单个博弈开始分析:
终止状态的SG值为
其他状态的SG值为所有后继状态的SG值的Mex值。
如果一个状态的SG值为
如果一个状态的SG值不为
也就是说,SG值的定义与先手必胜状态和先手必败状态的定义完全一致,因此该定义是正确的。
接下来分析多个子博弈的合成博弈:
如果合成博弈的SG值为
设有
设进行一次操作后,第
由于
由于进行一次操作后,第
如果合成博弈的SG值不为
设有
类比Nim游戏的证法,必然存在
因此必然存在一种操作,使得合成博弈的SG值变为
因此多个子博弈的合成博弈的SG值与先手必胜状态和先手必败状态的定义完全一致,因此该定义是正确的。
对于代码实现,求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 110 , M = 10010 ;int S[N], f[M];int k, n;int sg (int x) if (f[x] != -1 ) return f[x]; unordered_set<int > next; for (int i = 1 ; i <= k; i++) if (x >= S[i]) next.insert (sg (x - S[i])); for (int i = 0 ;; i++) if (!next.count (i)) { f[x] = i; return f[x]; } } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); memset (f, -1 , sizeof f); cin >> k; for (int i = 1 ; i <= k; i++) cin >> S[i]; cin >> n; int res = 0 ; for (int i = 1 ; i <= n; i++) { int x; cin >> x; res ^= sg (x); } if (res) cout << "Yes" ; else cout << "No" ; }
894.拆分-Nim游戏 题干 给定 规模更小 的石子(新堆规模可以为
问如果两人都采用最优策略,先手是否必胜。
输入格式 第一行包含整数
第二行包含
输出格式 如果先手方必胜,则输出 Yes。
否则,输出 No。
数据范围
输入样例: 输出样例: 思路分析 对于一堆规模为
设
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <bits/stdc++.h> using namespace std;typedef long long ll;const int N = 110 , M = 10010 ;int S[N], f[M];int k, n;int sg (int x) if (f[x] != -1 ) return f[x]; unordered_set<int > next; for (int i = 0 ; i < x; i++) for (int j = 0 ; j < x; j++) next.insert (sg (i)^sg (j)); for (int i = 0 ; ; i++) if (!next.count (i)) { f[x] = i; return f[x]; } } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); memset (f, -1 , sizeof f); cin >> n; int res = 0 ; for (int i = 1 ; i <= n; i++) { int x; cin >> x; res ^= sg (x); } if (res) cout << "Yes" ; else cout << "No" ; }